

The art of writing a great practice question
The art of writing a great practice question
Retrieve three themes to activate diffuse + focused learning. Give the PQ one good job. Apply four quality controls. Achieve a great PQ with density, depth, and/or realism.

Contents
Raise the standard—don't be lazy—because GPT-4 already writes more and better concept check questions.
Read the text actively and well enough to select three key themes (focused + diffuse mode). Identify crucial footnotes and go to their source.
The requirements of a good question: a short, unambiguous question at the end of the stem; only one key and that key is correct in the specific and the general; the stem is a complete problem by itself (the choices do not complete the question unless it’s an except for question); distractors are obviously false; quantitative scenarios are coherent
Quality controls (four ways to add care and polish): verify terms and definitions; reduce clutter; check presentation of numbers; calibrate difficulty level.
To level up to a bit of enduring artwork, add: density, depth, or realism
Conclusion
If learning is a religion, then practice question and answer (PQ&A) dialog is my favorite sacrament. I've written thousands of practice questions (PQs) to help Bionic Turtle’s customers prepare for the financial risk manager (FRM) exam. I've also replied >15,000 times to follow-up queries about my practice questions. We call it socializing the questions, and it's the true source—albeit time consuming—of my own expertise in finance. Sure, the point of socializing PQs is often to further explain, justify, or append to the solution’s initial version1. But it's also often to be alerted to an error (large or small), to identify imprecisions, to be challenged on interpretation, or to be plainly schooled by practitioners who know stadiums more than me. The PQs that I write today are better due this experience.
A good question meets the requirements. A great question is a small piece of art whose utility endures. Below I will try to capture how I approach the art. If you just want the checklist, GPT-4 generated this checklist from this article.
Brief preface
Practice questions (PQs) are either quantitative or qualitative; aka, conceptual. I’m not a fan of heavy word problems that straddle qualitative and quantitative objectives2. Qualitative PQs derive from learning outcome (LO) verbs such as explain, describe, or identify; e.g., “Identify the major risks faced by banks” leads to a set of qualitative PQs. Quantitative PQs derive from LO verbs such as calculate, compute, or apply; e.g., “Apply the GARCH (1,1) model to estimate volatility” must lead to a quantitative question because volatility cannot be understood without calculations3. Verbs like interpret or estimate can prompt either quantitative/conceptual question types. Also, the except for question type is special in the artist's toolkit, to be used when striving for density. A carefully written except for question can teach for months or years! Finally, I tend to parse the Q&A into five elements: Stem, choices [aka, options], key, distractors, solution, and explanation.
1. Don't be lazy (GPT4 is already better than your best lazy attempt)
The first requirement is to care enough to cultivate a high standard. Below are two snippets from GARP's end of chapter (EOC) questions. In order to lower expectations and conserve effort, they are called Short Concept Questions; aka, concept checks. Even before GPT-3.5, these questions were insufficient to the task. Today's large language models (LLMs) render them superfluous. With GPT-4 (and its plugins), the machine writes better concept check questions. Not convinced? It took less than two minutes to train/ask GPT-4 to generate 20 true-false questions about the correlation material (below right); here they are and they’re quite good. I perceive the LLM created a better list than GARP’s printed EOC concept checks. Further, GPT-4 can keep going. And I can dialog with it! We no longer need humans for lazy concept checks.

2. Study the text well enough to select three key themes
In reference to a chapter or academic paper, the first choice is, what do we ask about? To write a good question requires knowing the material. For myself, this means that I need to actively read the chapter several times. The question writer doesn't need to know as much as the author, but the writer must be a capable concierge to the material. If there are numerical exhibits, I usually re-create them in Excel. It’s important to read all footnotes and discern incidental footnotes from crucial footnotes. When the footnote is crucial, I download and read the reference. For example, GARP’s operational risk material references the ORX taxonomy via footnote but that taxonomy is also crucial to the readings. Therefore, I download (the free version!, at least) ORX resources, read them, and make sure they are saved in our supporting resource (dropbox) folder. This material is the “iceberg below the surface” that gives us depth, and is available in case a customer wants to talk about it later. My point here is: I think we need to read the footnotes. We don’t need to go down most alleys, but some readings are primarily based on other material that is referenced in the footnotes.
In general, I re-read the text until I can confidently articulate three key themes (each theme informs a PQ), preferably ordering them in importance. Why prioritized themes? Because this self-exercise forces me to actively read the text on two levels. First, by zooming into the details as an analyst. Second, by zooming out (ideally on a different day) to a wider perspective. The zoom-out view sometimes provokes me to connect the chapter to other parts of the syllabus. Many years ago, I took Barbara Oakley’s renowned course Learning How to Learn. She taught me the difference between the brain’s focused mode and its diffuse mode. I’m a big believer in creating space for the diffuse mode.
Most book chapters or academic papers have two dozen or more potential concepts (many of which are ephemeral details that don’t really matter in the long run) but fewer than five important themes. For example, the learning objectives (LOs) for the FRM's P2.T7.C4 on operational risk measurement are daunting4:
Describe and distinguish between the different quantitative approaches and models used to analyze operational risk. Estimate operational risk exposures based on the fault tree model given probability assumptions. Describe approaches used to determine the level of operational risk capital for economic capital purposes, including their application and limitations. Describe and explain the steps to ensure a strong level of operational resilience, and to test the operational resilience of important business services.
After carefully reading the chapter, I selected the three themes that informed my PQ set for the chapter:
Factor models
Loss distribution approach (LDA)
Operational resilience
In this example, thematic curation was the most important step. The resulting questions effectively blanket the entire chapter; e.g., the first question naturally includes details like the fault tree model referenced in the LOS.
Learning objectives and outcomes (LO)
The CFA publishes learning outcomes while the FRM publishes learning objectives. Objectives are goals or intentions, while outcomes are measurable achievements5. In my experience, the difference between these two nouns is less important than the quality, specificity and verb choice of the LO. For videos, I developed a three-step workflow to map a list of literal LOs into an analogous but slimmer set of durable intentions/outcomes. An ideal set of LOs complements the text by highlighting durable concepts and even links the text to practical concerns.
But I'm not confident any of these LO artifacts are the future. Their drawback is too often they are an overwhelming turn-off. I think the modern approach is to jump right into a small project. To learn regression, the old way is theory first: step slowly through the assumptions, passively read about each of the elements, and try not to give up. The modern way is to grab some real data and do little regression projects. Maybe learn some of theory later, depending on dialog the emerges from the project. I have likened this to the difference between “go read this cookbook" (per my instructions as the teacher) versus "just start cooking, watch me do it, if you like" (then let’s talk about it as we go, asking questions when we get stuck. What about theory? On demand, if at all).
3. The requirements
A good PQ has several requirements but generally has only one job to do. The job is to reinforce a concept or small cluster of related items (e.g., definitions). We attend to many details in service of the one job. These are the requirements:
The question sentence itself must be unambiguous; should be the stem's final sentence6; and probably contains only a few words. Even if the context is long, the best questions are short. If we cannot edit to achieve a short final question sentence, then we should examine whether our structure and logic are cogent. A long, rambling question sentence is typically the symptom of an imprecise or illogical question.
For example, I had a question on hedge fund styles where the stem concluded with this question: "Each of these descriptions above is consistent with its style category, EXCEPT which appears to be inaccurate?" My colleague Kata Martinez observed that, as written, there was more than one interpretation of the question. Not good!7 The edited version broke the sentence into two and concludes with a cleaner actual question: "Each of these descriptions is consistent with its strategy (aka, style) category EXCEPT for one. Select the fund that is NOT consistent with its advertised description."
There should be only one correct answer.
The solution should be correct in the specific and, if possible, also correct in the general. By specific, I mean that the Q&A should find convincing support in the text. By general (as an aspiration), I mean that the Q&A should survive in the wild world of actual practitioners. As a teacher, this is important to me: I want the question to align with the way practitioners actually talk about things.
For years GARP represented foreign exchange (FX) quotes contrary to actual practice. For example, they would refer to the Swissie as CHF/USD 0.9200 because 0.920 swiss francs per $1.0 dollar appears would look like CHF/USD if it were an arithmetic fraction. But practitioners use USDCHF or USD/CHF to signify USD as the base currency and CHF as the quote currency. Further, currencies have rank and the Euro has the highest priority. As such, our default presentation is always EURUSD $1.0600 rather than the equivalent USDEUR €0.9434 = 1/1.06008.
This requirement (i.e., that the question survive specific and general testing) tends to eliminate many “most likely” and “least likely” questions! Personally I write these very rarely because I want my questions to have decisive keys.
The stem should contain the entire question such that the stem does not depend on the choices. The options should not contribute to the question. If we delete the choices, what remains should still be an answerable question.
This is especially true of a quantitative PQ: the learner should be able to find the correct solution before even viewing the choices.
There are exceptions. An important exception is the "except for" question. Why? Because an “except for” is a set of true/false questions.
Quantitative PQs should have a coherent underlying construction. In general, the best way to do this is to build (or code) the underlying scenario in a spreadsheet. The reason to do this is to avoid mistakes or imprecisions that might only be identified subsequently under the stress-testing of a diversity of learners types and levels. For example:
If the stem setup includes a yield curve, the scenario should be constructed in Excel (or coded). This will expose inaccuracies or careless assumptions. Several of GARP's questions supply three interest rate levels to crudely represent a yield curve, but the solutions aren't self-aware that some metrics (e.g., DV01) vary within the setup. These drawbacks often penalize the learner who know more, because it is this learner who tends to see deeper with less dependence on rote memorization.
Another persistent problem in the FRM relates to portfolio value at risk (portfolio VaR) where the LO set is given by: “Define, compute, and explain the uses of marginal VaR, incremental VaR, and component VaR.” Each of the above metrics can be solved in at least two or three ways. A coherent scenario returns the same marginal VaR regardless of the approach. But because GARP simply populated the stem's display exhibit without an underlying scenario, many historical PQs had possible solutions that weren't among the choices.
Distractors should be obviously false on inspection. Distractors should not unfairly compete with the correct choice; aka, the key. Many PQs in circulation do violate this rule, but I disagree with their attitude. Why? Because a great PQ wants the learner with the right idea and execution to quickly identify the key. In American football, it's totally fair to execute a flea flicker (a pass that looks like a run) or draw play (a run that looks like a pass). But we aren't trying to defeat a learner with clever deception.
In quantitative PQs, distractors should not be too near to the key. This is a pet peeve of mine because finance has a lot of valid approximation methods (nobody can know them all!), and I generally want the PQ to reward the use of a valid approximation. If the correct answer is 3.141593, do not give 3.2 or even 3.0 as distractors. Give the number a lot of room to breathe. In this question about a mortgage loan9, my responses {a. $550,733, b. $691,805, c. $703,294, d. $871,805} are almost too tightly crowded. As you can see, I live dangerously ;)
This question by GARP about the Merton model is just terrible on multiple levels. One problem is that the taker is supposed to use an approximation (of already an approximation) to solve for three numbers {5.11, 5.79 and 5.58} that are too proximate to each other. It is uncool to proximate an approximation of an approximation!
4. Quality controls: four ways to add care and polish
Once the question is drafted, we can check it for quality10. In my workflow, the quality checks include terminology, simplifying edits, number checks, and difficulty level.
First, the most important quality control act is to verify the terms (terminology) and definitions. Much of finance reduces to definitions and applied math. Math communicates precisely with symbols, but the bridge to language(s) is not always short and straightforward (even before non-English language considerations). We shouldn’t confuse new learners with imprecise terms. In the FRM, here is a tiny fraction of the semantic minefields where GARP has confused our learners:
Probability of default (PD): hazard rate (aka, default intensity), conditional PD, cumulative PD, unconditional (aka, joint) PD, marginal PD
Counterparty exposure: mark-to-market, value, exposure, current exposure, credit exposure, future value, potential future value, potential future exposure, expected positive exposure (EPE), and effective expected positive exposure (EEPE)
Value at risk (VaR) approaches: relative, absolute, delta-normal, normal linear, variance-covariance, parametric, analytical. This extends to surplus at risk (SaR) for pensions: a typical scenario has three valid SaR numbers, so it is insufficient to simply ask for the SaR.
Of course, I've made plenty of my own semantic mistakes. My own question P1.T4.902.1 asks …
"In terms of their current theoretical prices, which bonds are, respectively, the cheapest and most expensive (among the four)"
… but a customer observed that "cheap| expensive" are open to interpretation, and I should have used "highest | lowest theoretical price."
We must verify the potential definition set of all crucial finance terms. Even in math and statistics, we should check beyond the specific reading to general applications. For example, value at risk (VaR) is a quantile. That's an important term and it turns out there can be up to nine quantile algorithms.
Second, we should edit to reduce clutter. If the question includes a chart, we can often improve a chart by (i) deleting chart-junk or (ii) adding labels for readability. Below are three versions of a setup for the optimal number of hedging contracts. The best version includes text labels (“correlation”) and mathematical symbols, “ρ(S,F)”. This sort of redundancy is helpful.

Below is a mortality table by GARP (upper panel) and our version (lower panel). An actuary will know the exact definitions, but for our purposes, we want to clarify by matching these probability concepts with their definitions elsewhere in the program.

Below is GARP’s setup (top panel) and our analogous setup for a similar question. Rather than ignore the sample/population choice when standardizing, our problem embraces the difference and uses the occasion to surface a small but realistic user choice that arises! It’s tiny but I don’t like their left-aligned numbers because it makes it just a tad harder to compare numbers.

Third, quantitative PQ should be careful about the presentation of numbers. We cannot write great quantitative PQs without an awareness of significant figures. I am careful to include one insignificant trailing zero. For example, if the exact correlation, ρ, is 0.37, then I will write "ρ = 0.370" to help the reader understand it is not rounded; i.e., 0.37 could be a rounded 0.372 or 0.368. We should take particular care with interest rates. We should write "the riskfree rate is 5.0%" not "the riskfree rate is 5%" because the latter might leave somebody wondering whether it is a rounded 4.9% or 5.1%.
Fourth, we can check (and calibrate) the desired difficulty level. As our customers know, our bias is on the difficult side. I prefer my question is too hard rather than too easy. More recently, I deliberately target two levels: brand new learner versus experienced learner. My hunch is LLMs might help semi-automate difficulty calibration.
Red herrings: Unless the red herring is key part of the question’s “one job to do,” I’m not a big fan of them. I think a good stem is clear and reliable.
5. Leveling up to a bit quality artwork: density, depth, and realism
The above is my view the required ingredients. Below are some optional tendencies that increase the odds of creating a quality question that endures; aka, art. What's my evidence? It is simply that these features have succeeded with customers over time. Because we socialize, a question is only great if others validate it over time in conversation. The best questions provoke further exploration. Often, I’ve thought the "case is closed" on a concept--especially if it seems basic--but somebody finds an angle that prompts next-level (e.g., n+1) thinking. I used to believe I mastered basic concepts, but I no longer believe that. Our forum has convinced me that no idea is ever completely plumbed.
Artfully great questions and answers (Q&As) tend to be either very short or long (often due to a high-quality solution). In my own practice, the artful features of great questions tend to reflect the virtues of density, depth, and/or realism11.
Density as Quality
Density Example #1
The two PQs below are dense in the stem. The topic is risk mitigation. Both are “except for” questions. The reason is that the PQ wants to review each cluster carefully via the distractors that are themselves true statements.

Density Example #2
Our time-series reading includes the hard concept of covariance stationary. My question below is super bland, but it tackles the definition with density by asking about eight of the patterns in the readings (something the reading doesn’t do very well, so this Q&A set becomes an efficient cheat sheet).

Density Example #3
The one-sided hypothesis test is notoriously challenging, so this PQ smoothers the hard idea with density. Each of the “Albert says, Betty says, Chris says” … is based on questions we’ve received on the forum (so we know they are stumbling blocks): customer support questions can be an ideal source for future questions!

Depth as Quality
Depth Example #1
This PQ set is about the Black-Scholes and its lognormal property. There is a mix but each has depth. I’m proud of 814.1 which is short but sweet with plenty of depth potential (as the subsequent thread showed). A mere 63 words supply five numeric assumptions, including redundancy to help with clarity; i.e., “OTM”, “T = 1.0 year”.

Depth Example #2
This PQ is about exotic (aka, non-standard) options, in this case choosers and barriers. Like almost all our exotic option question sets, each Q&A is supported by a dynamic pricing model so we can handle follow-up discussion.

Realism as Quality
By realism, I mean that the practice question goes to the trouble of illustrating a realistic application and/or employs a plausible dataset.
Realism Example #1
Below is the partial stem of multivariate regression and its diagnostic that tests a realistic model to predict house prices. The question provides a link to code for further exploration.

Realism Example #2
Below is a time series model based on actual GDP data. Again, the learner can link to the code on GitHub.
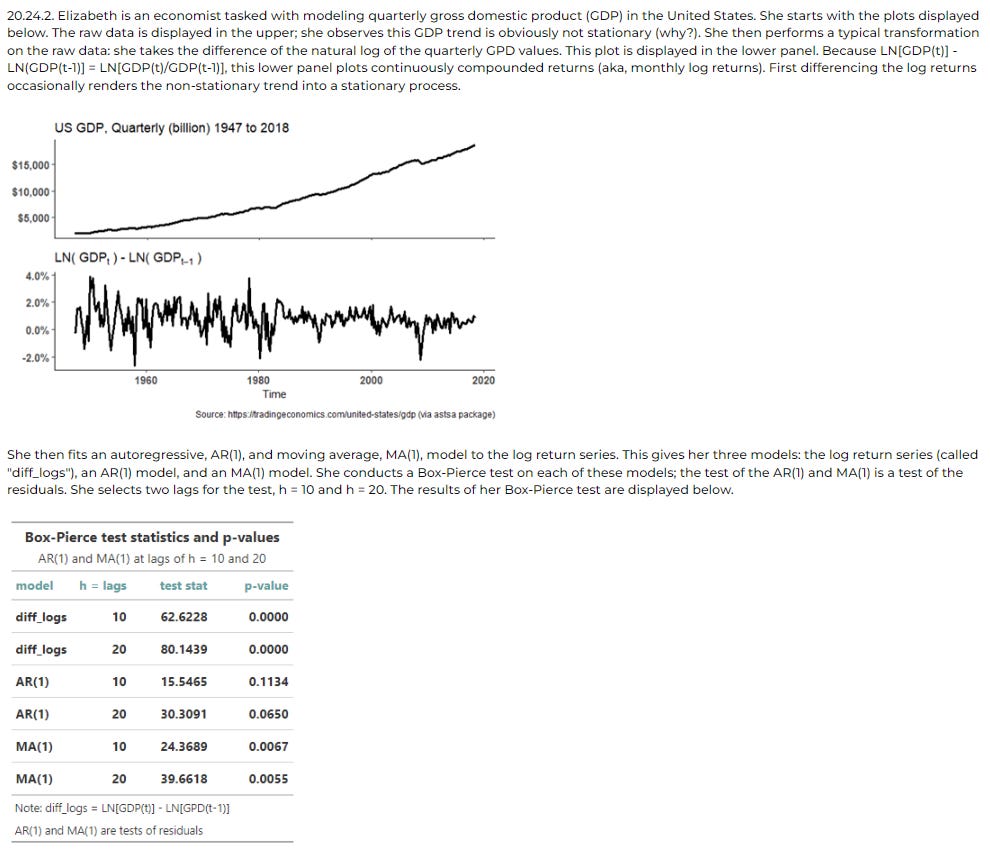
Realism Example #3
This question performs a regression that applies the Fama-French three-factor model. To work with actual data is entirely different than passively reading the usual textbook material on this famous model.

Conclusion
Generative AI is a gift for those who want to make a impact with a high standard. We can finally choose to delegate things like lazy concept checks. I’ve recommended active reading (focused + diffuse) to retrieve themes the inform question selection. Then we want to be careful about giving the question one good job. Preferably the learner can validate the Q&A in the specific source and in general practice. The most important quality control is the verification of terminology and definitions. Finally, we can increase density, add depth, or introduce realism to craft a great question!
I might explain or try to justify a practice question, but I try never to “defend” it. Teachers are always open, never defensive. We’ve got to keep an open mind. Customers are very forgiving if you acknowledge and respond to feedback. It isn’t about who’s right or wrong—which sometimes changes over time anyway!—it’s about participating in other people’s improvement and our own self-improvement.
By heavy word problem, I mean a quantitative question buried or wrapped too heavily in a narrative or story. The reason I dislike this approach is that it adds a semantic (interpretive) layer to a question that already has an unequivocal mathematical (symbolic) expression. This often creates two questions in one: first, the burden to decipher the problem statement, then second, actually solving the problem. Especially if the quantitative question is itself medium/hard, I don’t like forcing the reader to decipher how the assumptions are arranged. Give the reader a clean set of assumptions.
Don’t get me wrong. I do write many long narrative stems (e.g., Alice is a risk manager at a bank and the Board asked her ….). But they are always to add clarity, never to obfuscate or create an additional puzzle. In most cases, my long setups are expressly to reinforce important items related to the question.
I can’t stress this enough, and volatility is just one example: until you perform a volatility calculation, you don’t know what it really means. If I say this stock “has a volatility of 23%”, I’ve said nothing so far. It’s probably not normal so the 68-96-99.7 rule doesn’t apply; it’s probably per annum but scaled (per the SRR that unrealistically assumes i.i.d. such that it’s implicitly over- or under-stated); maybe it’s implied but more likely it’s an updated estimate based on a historical window; if historical, likely GARCH or EWMA but not necessarily; and what’s the window length and periodicity of returns? Did we assume a zero mean? How did we calculate the returns? A dozen little items come to the surface when we go to actually calculate volatility, learning a lot in the process, and discovering that “volatility” can be quite sensitive to various choices and assumptions. After calculating a hundred volatilities, we will finally understand why Carol Alexander says “Volatility is unobservable. We can only ever estimate and forecast volatility, and this only within the context of an assumed statistical model. So there is no absolute ‘true’ volatility: what is ‘true’ depends only on the assumed model” (Market Risk Analysis, Volume II.3.2.4).
For this reason, a quantitative concept implies a quantitative question. It is very difficult to write an effective qualitative question about volatility. Such examples of qualitative-on-quantitative PQs do circulate but we’ve found they are likely to be counter-productive.
2023 Financial Risk Manager (FRM) Learning Objectives. Part 2. Operational Risk and Resilience. Chapter 4: Risk Measurement and Assessment [ORR-4]
The FRM also has “broad knowledge points” that introduce each of its 10 major topics (Part 1 is topics one to four; Part 2 is topics five to 10).
My colleague Charles Naylor educated me on this interesting fact: when prompting (aka, prompt engineering) a large language model (LLM), the position of the actual question within the context makes a material difference (a “big enough improvement”). He gets the best result when the question/instructions are at the very end of the prompt/context window. He cited this research that finds “performance is often highest when relevant information occurs at the beginning or end of the input context”.
As you are probably aware, many task takers (including myself) start with the question at the end of the stem: we were taught to read the question sentence first. I think it’s a good tactic. Just another reason why the question sentence itself must be super clear and without multiple interpretations.
We decided early to utilize practitioner conventions for FX quotes. It took a few years but GARP eventually switched over too.
23.3.1. Three years ago, Mary purchased a house in the United States. Her down payment was 20% of the $900,000 purchase price; therefore, the original balance on her mortgage loan was $720,000. Her loan was a typical 30-year fixed-rate, fully-amortizing loan with an interest rate of 6.0% per annum with monthly compound frequency. As of today (i.e., exactly 36 months after origination), which of the following is nearest to the loan's outstanding principal balance? Source: BT PQ P1.T3.23.3.1.
You can see why my PQ workflow is chunked over several days: active reading requires two different days (focused vs diffuse); drafting and editing are different days; quality control is a different day; and artful improvement another day. That’s six different days, ideally.
Sources for the following PQ illustrations:
Depth #1: BT P2.T7.23.6. Risk Mitigation
Depth #2: BT P1.T2.20.21. Stationary Time Series: covariance stationary, autocorrelation function (ACF) and white noise
Density #3: BT P1.T2.20.14 Hypothesis testing
Depth #2: P1.T4.814. The lognormal property of stock prices and the assumptions of Black-Scholes-Merton (BSM)
Depth #2: P1.T3.730. Chooser and barrier (exotic) options (Chapter 26 cont.)
Realism #1: P1.T2.20.19. Regression diagnostics: omitted variables, heteroskedasticity, and multicollinearity
Realism #2: P1.T2.20.24. Stationary Time Series: Box-Pierce test and model selection with AIC and BIC